Increasing Fine-tuning Efficiency
llms Overview
In my previous post, I explored fine-tuning the BERT model with LORA on my Mac. Here, I look at improving training efficiency, which can allow for faster iteration and a quicker path to business outcomes. This HuggingFace post highlights the various levers available to improve efficiency. I experiment with 4 dimensions: gradient checkpointing, gradient accumulation, choice of optimizer, and LORA layers. I started the experiments on my Mac w M1, but eventually moved to Colab (T4 GPU) because background processes often interferred with time metrics. All graphs are from WandB and the scripts are here.
Gradient Checkpointing
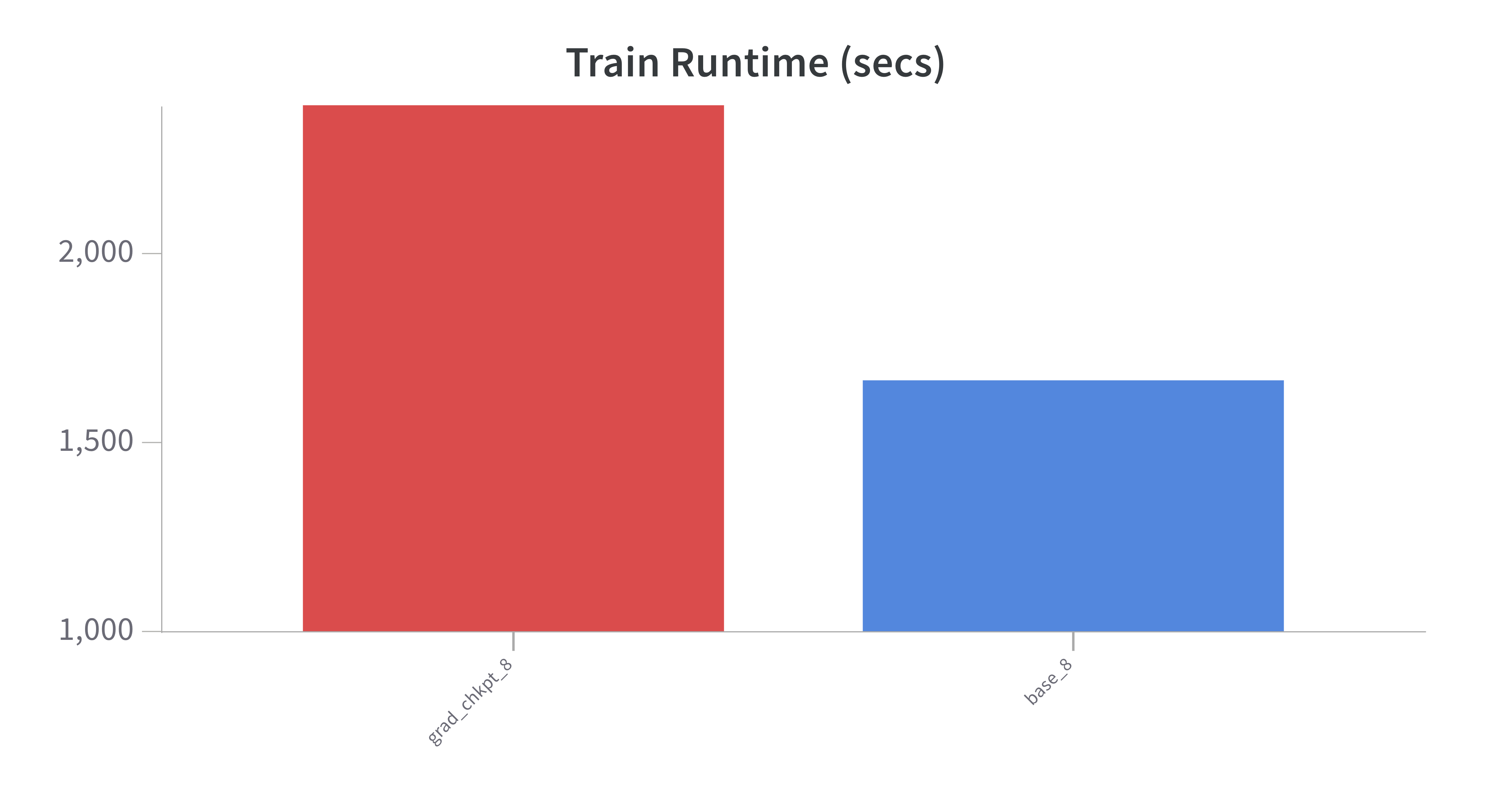
Gradient checkpointing strategically stores some gradients during the forward pass, but not all. It then re-calculates gradients as needed. The trade-off is decreasing memory requirements and increasing processing time: it take longer to train, but allows for larger batch sizes, which improves performance. Indeed, increasing batch size to 16 with the equivalent number of training steps yields an improvement of accuracy to 0.92 (not shown).
Results:
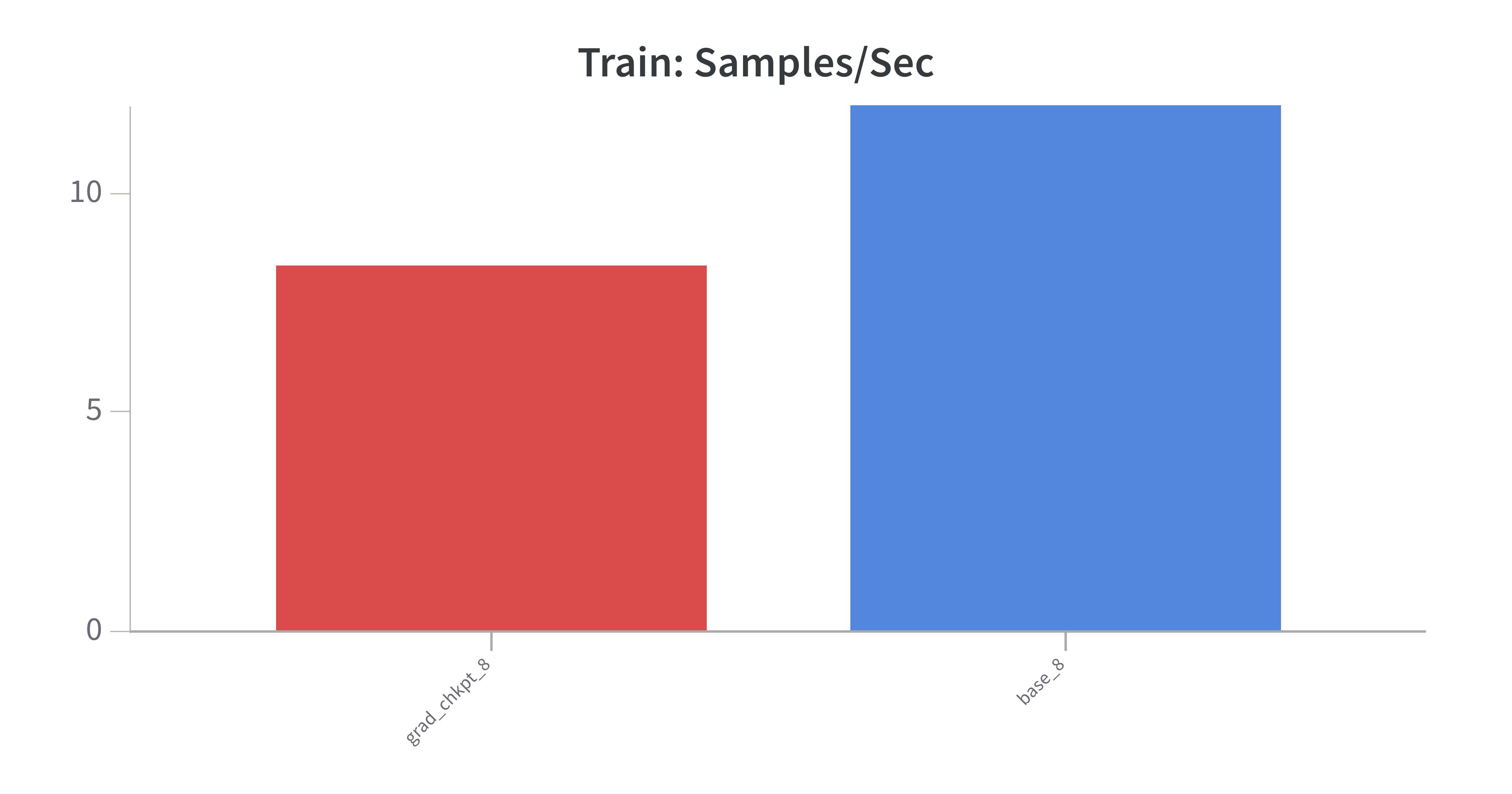
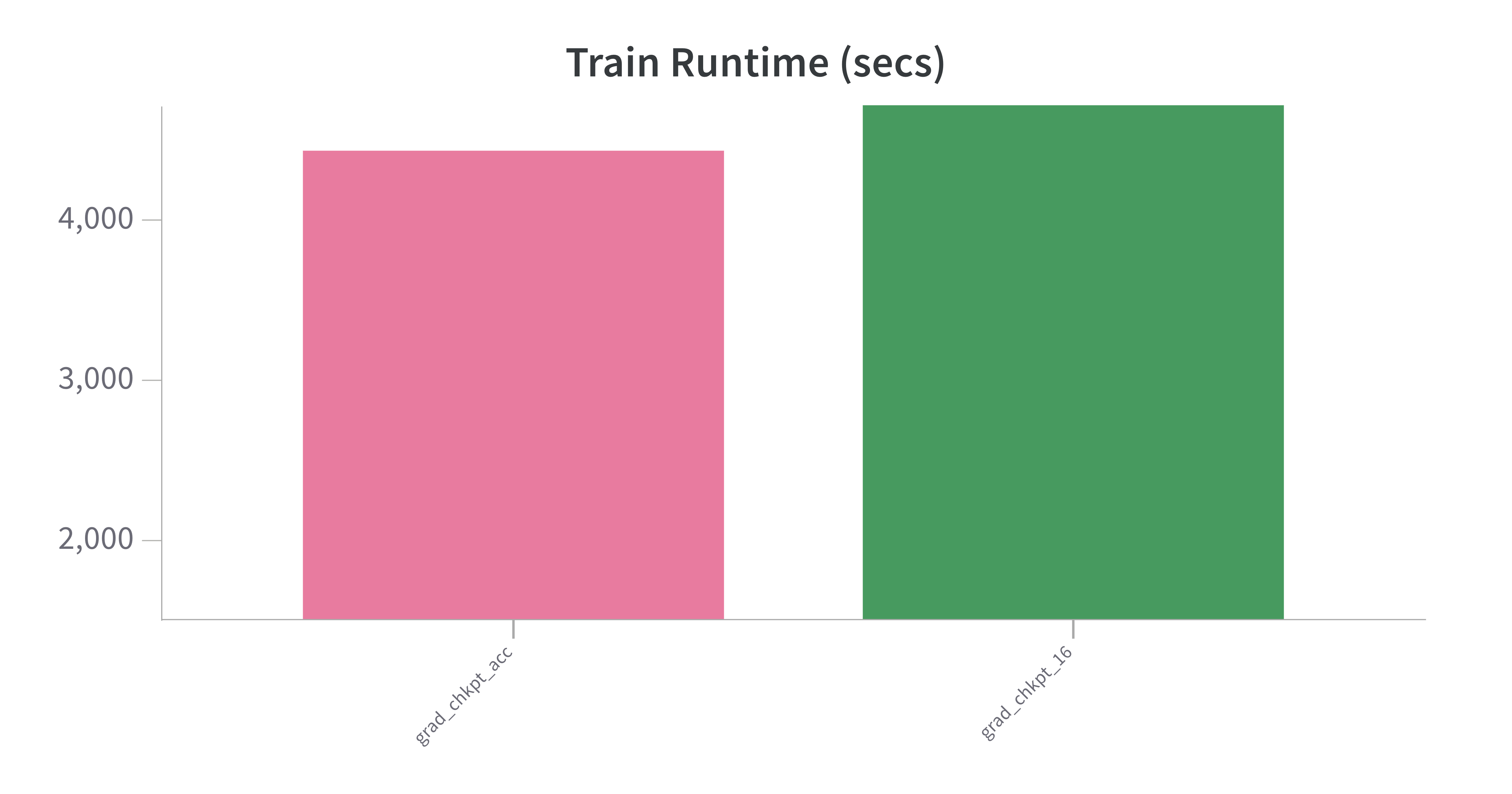
- As expected, checkpointing results in slower training time, in this case 50% longer. It processes ~30% less samples per second.
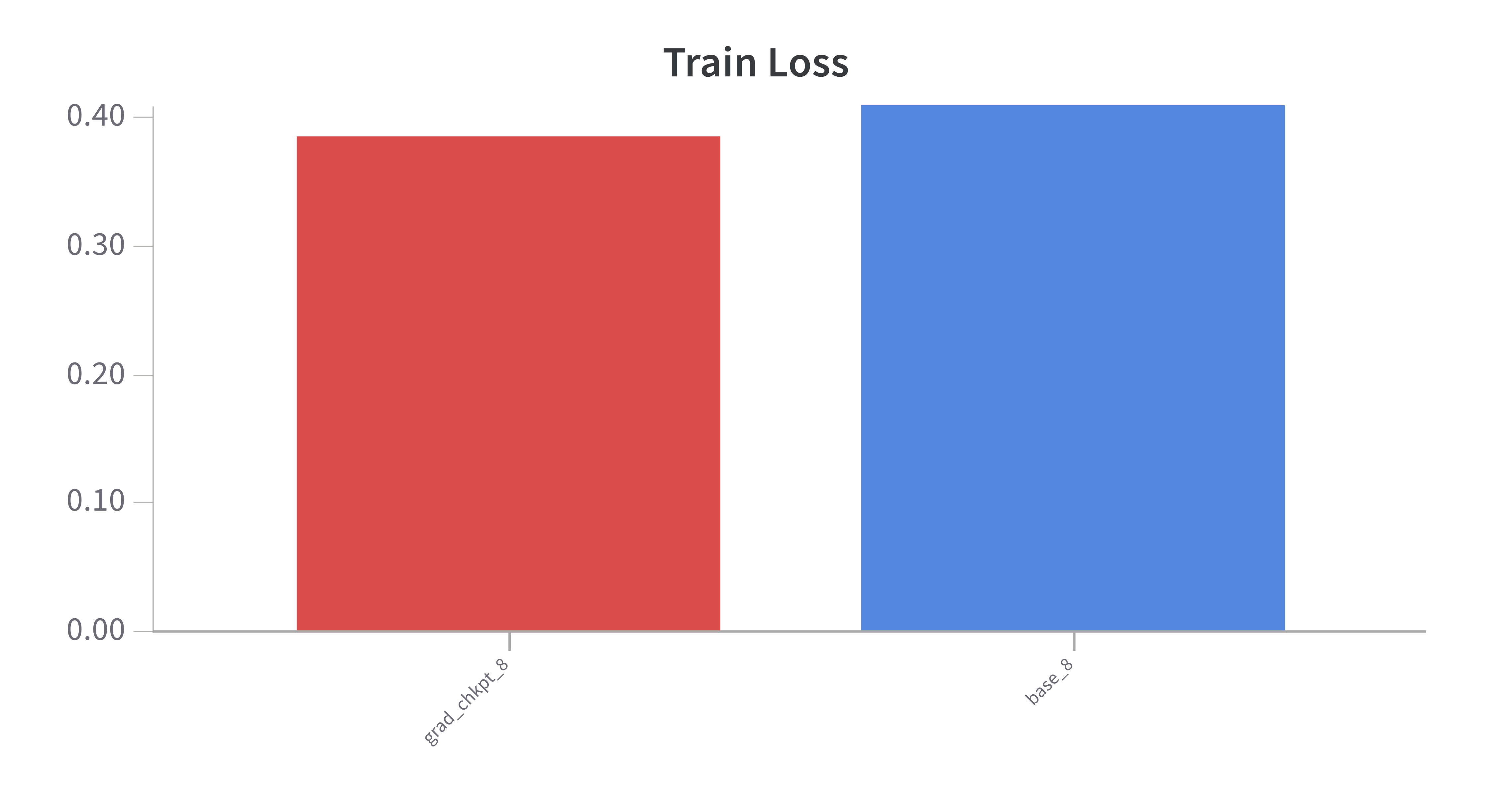
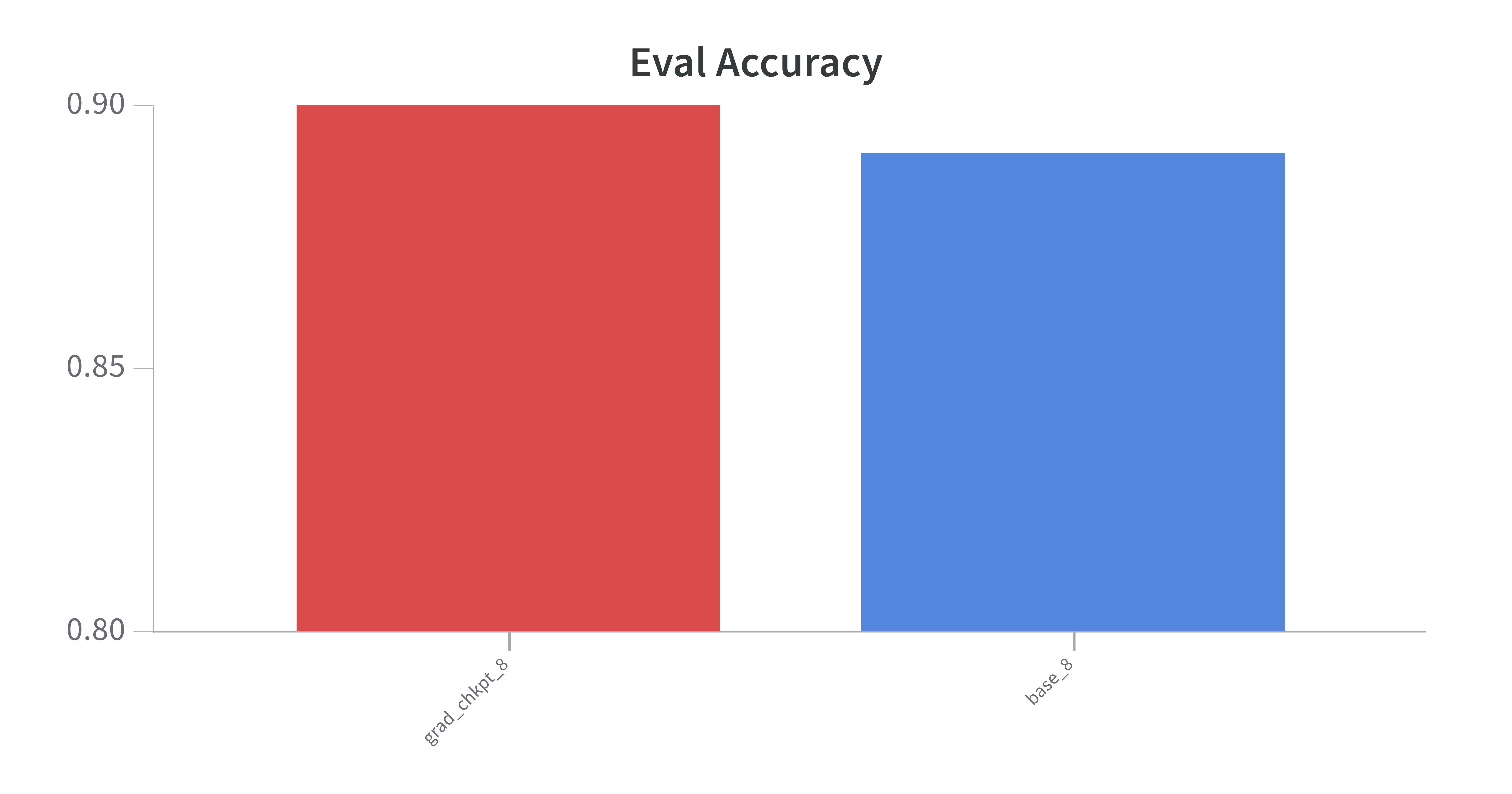
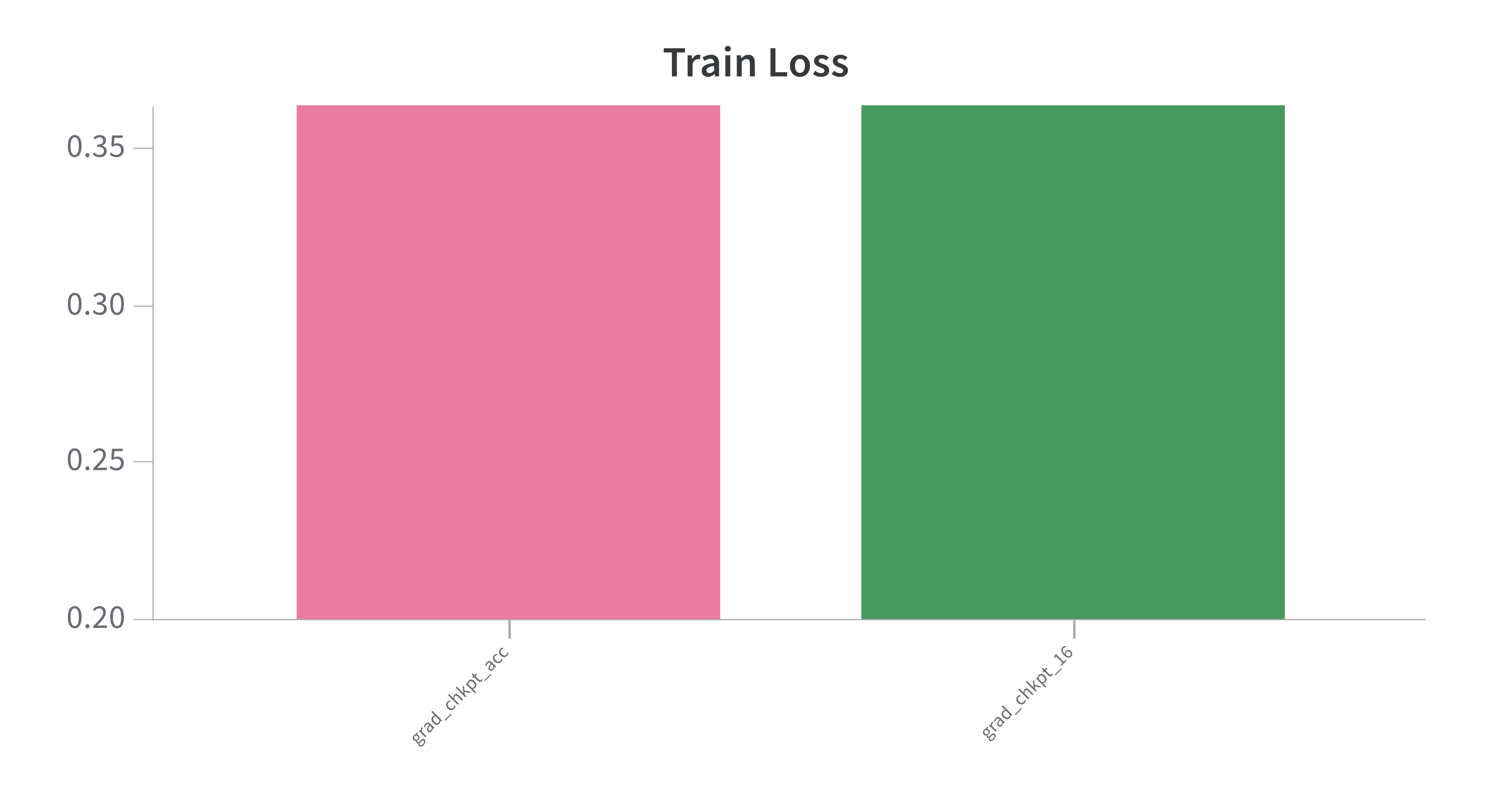
- Model performance is roughly inline with the baseline, which is expected: Checkpointing had a slightly better training loss and accuracy on the evaluation set of 89% (baseline) v 90% (w chkpting).
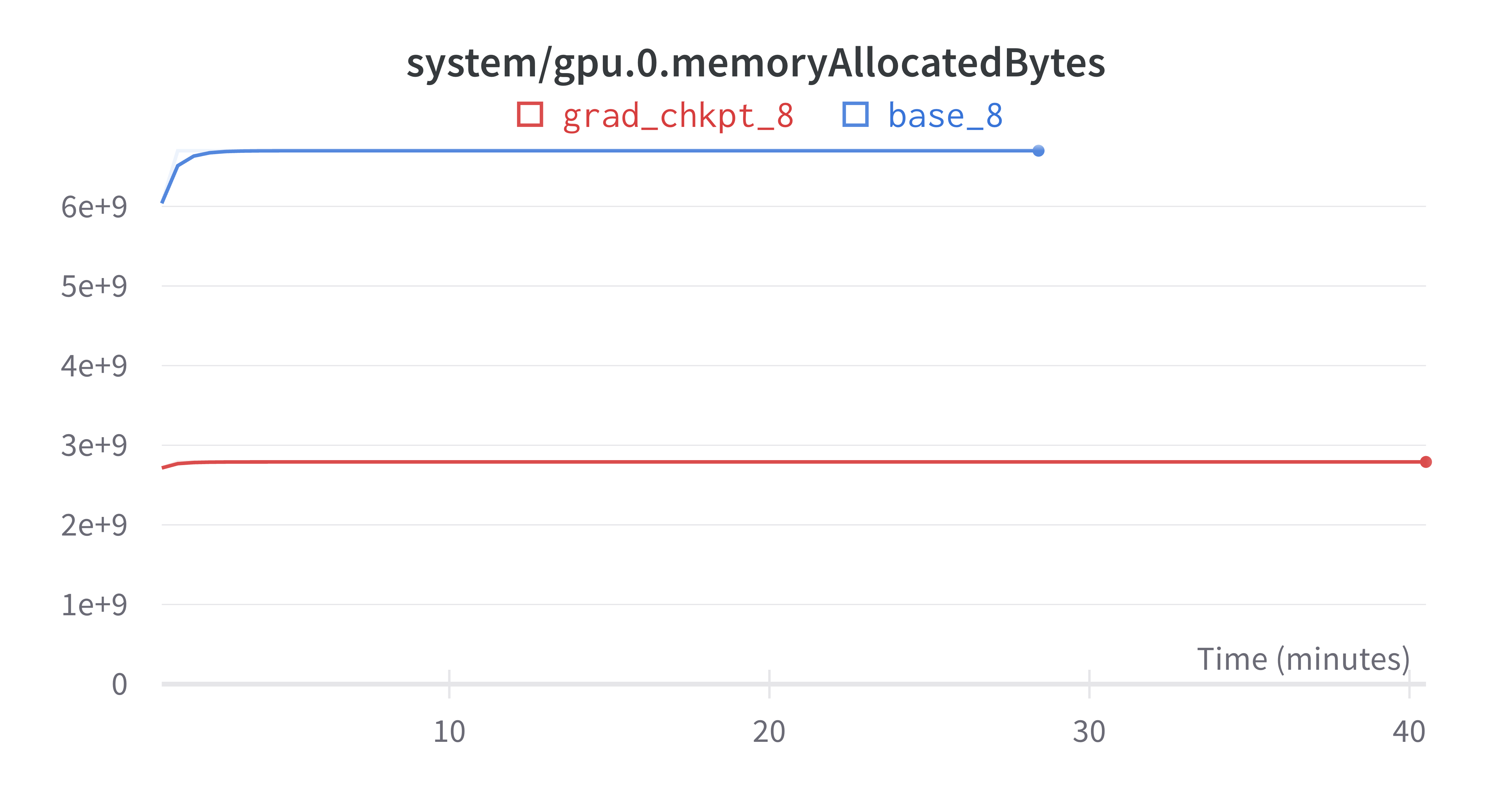
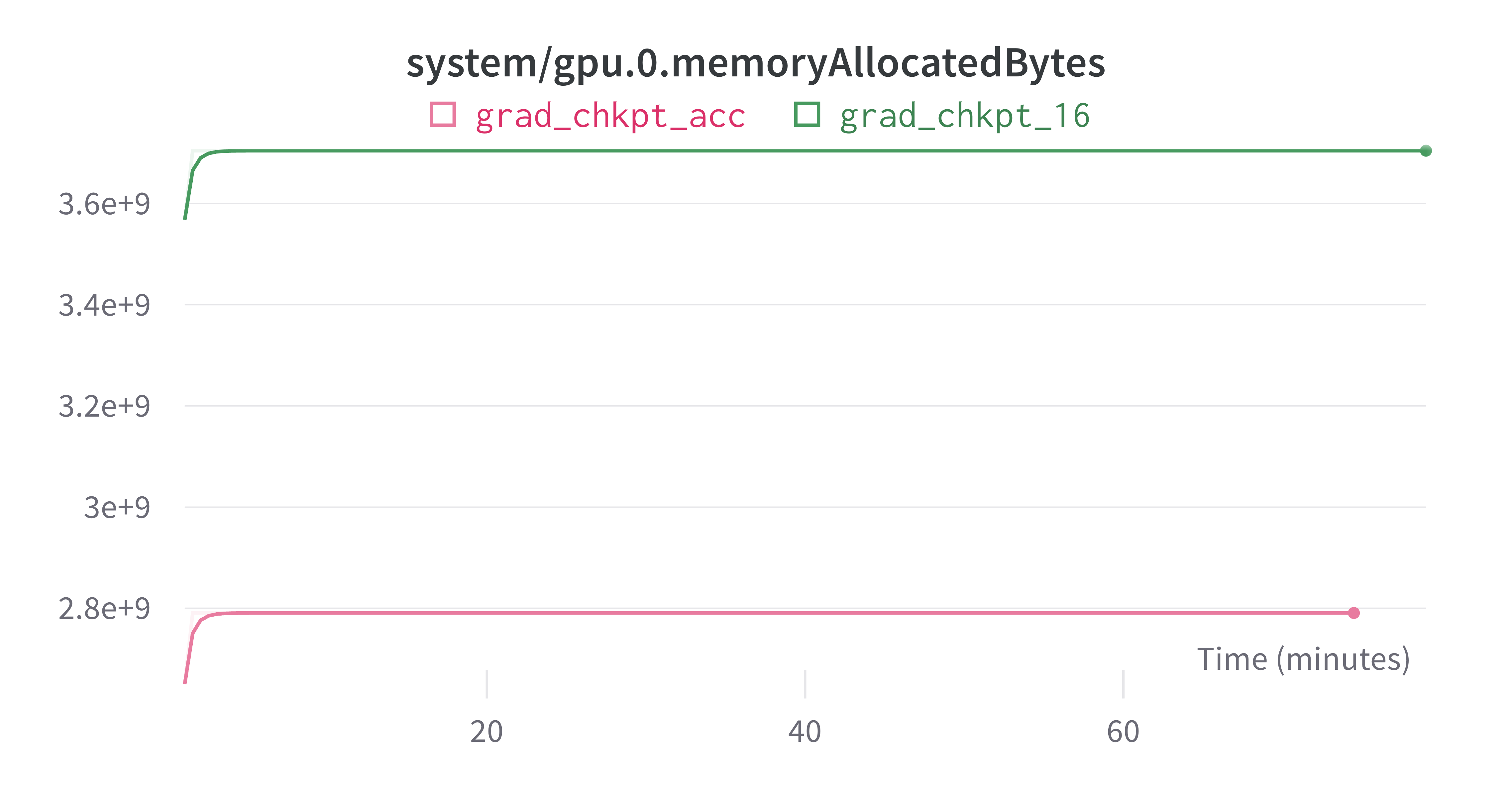
- Memory requirements and I/O writing requirements are less than 50%, given the lack of need to store gradients. Hence allowing for larger batch size, which improves performance.
Gradient Accumulation
Gradient accumulation is a very effective method for increasing the batch size without increasing the memory requirements. The idea is to accumulate the gradients over multiple batches and then update the weights. The gradient_accumulation_steps parameter in the TrainerArguments class controls this. The documentation states that the batch size is per_device_batch_size * gradient_accumulation_steps. In my experiments, I used a batch size of 8 and gradient accumulation steps of 2, which is equivalent to a batch size of 16. Note that on my Mac, I am unable to achieve a batch_size of 16 because of memory constraints: the training time required was 10x batch size 8. The comparisons below are using Colab and compares batch_size 16 to batch_size 8 with gradient accumulation of 2 steps, both using checkpointing.
Results:
- The training loss is equivalent, as you would expect because the two runs should be equivalent. The evaluation loss was lower, but this could be due to the random choice in datasets for each run. In hindsight, I should have set the random seed for this so that each run was equivalent.
- The important point is that gradient accumulation made the larger batch_size possible, was 5% faster and used less memory, all while being equivalent to the case of checkpointing with batch_size 8.
Optimizer Choice
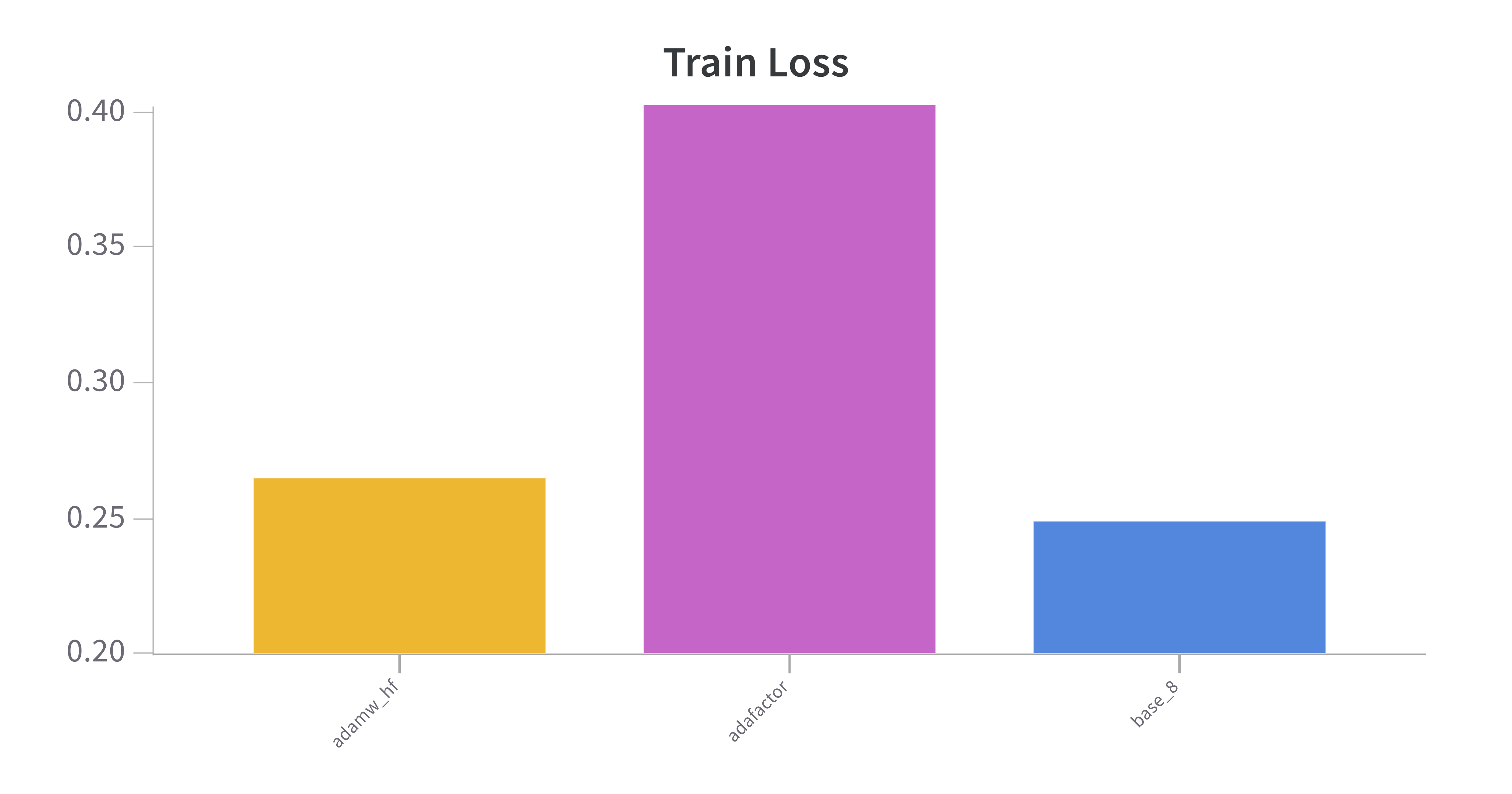
Optimizer choice can improve / deteriorate efficiency and affect performance. I found that adamw_torch was very effective and efficient when comparing it to adafactor and adamw_hf.
Results:
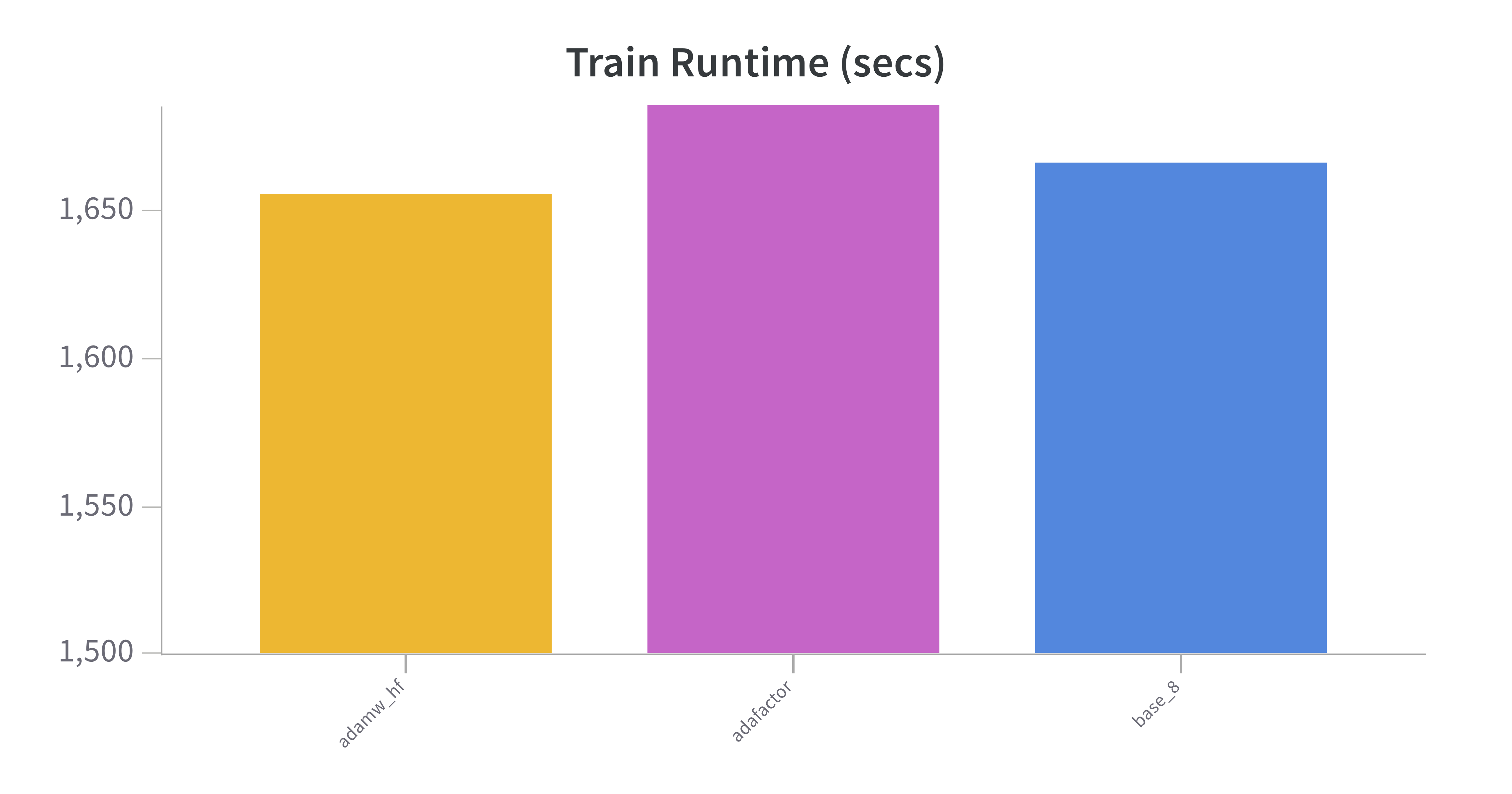
- All 3 optimizers clocked in at approximately the same training time.
adafactorperformed significantly worse andadamw_hfwas slightly worse.- Surprisingly,
adafactorwas supposed to take up less memory because it doesn't store gradients, but occupied the equivalent of the other two optimizers. This might be due to the very small amount of parameters introduced when training LORA and would become more pronounced if more models were being trained.

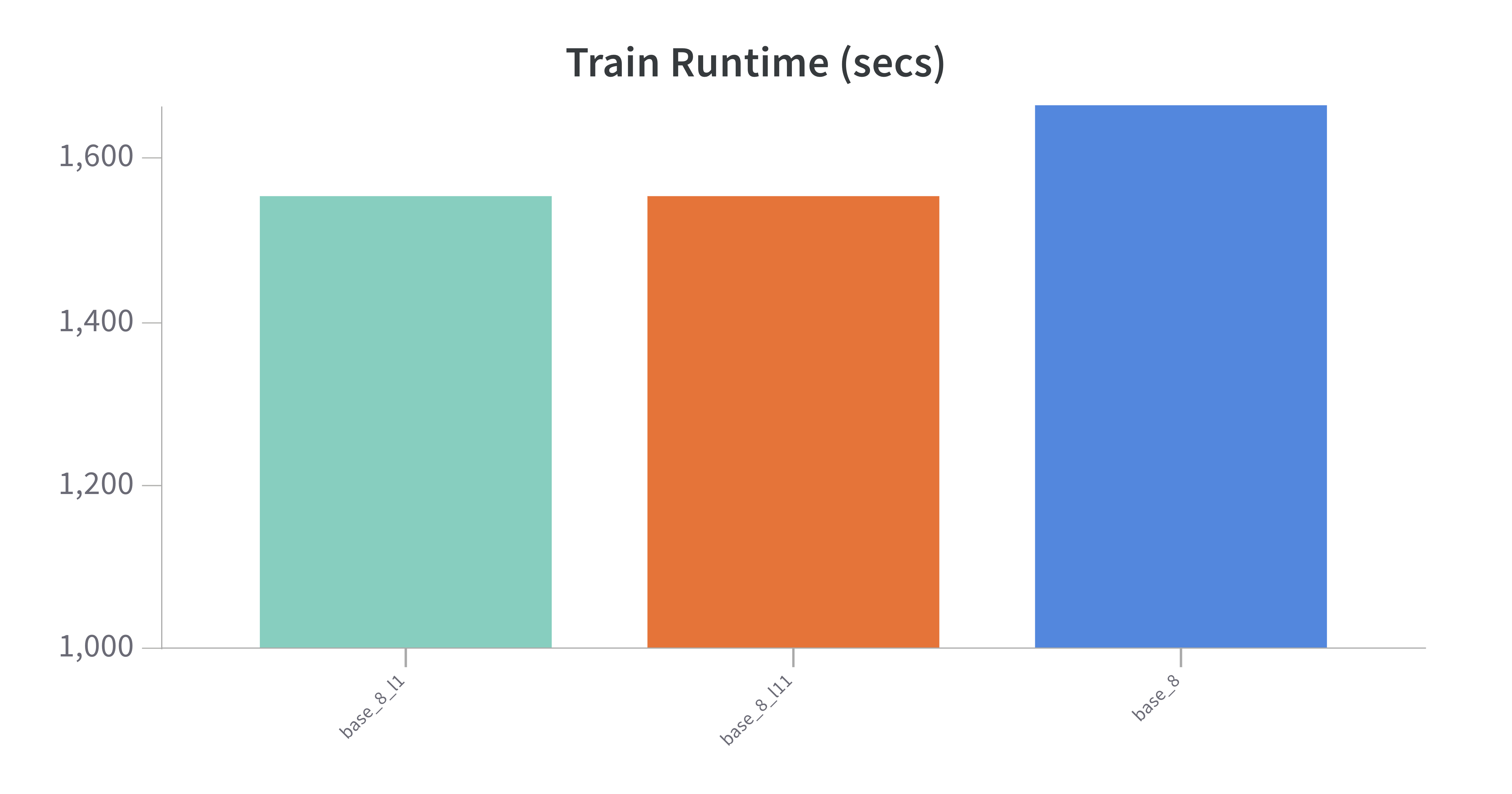
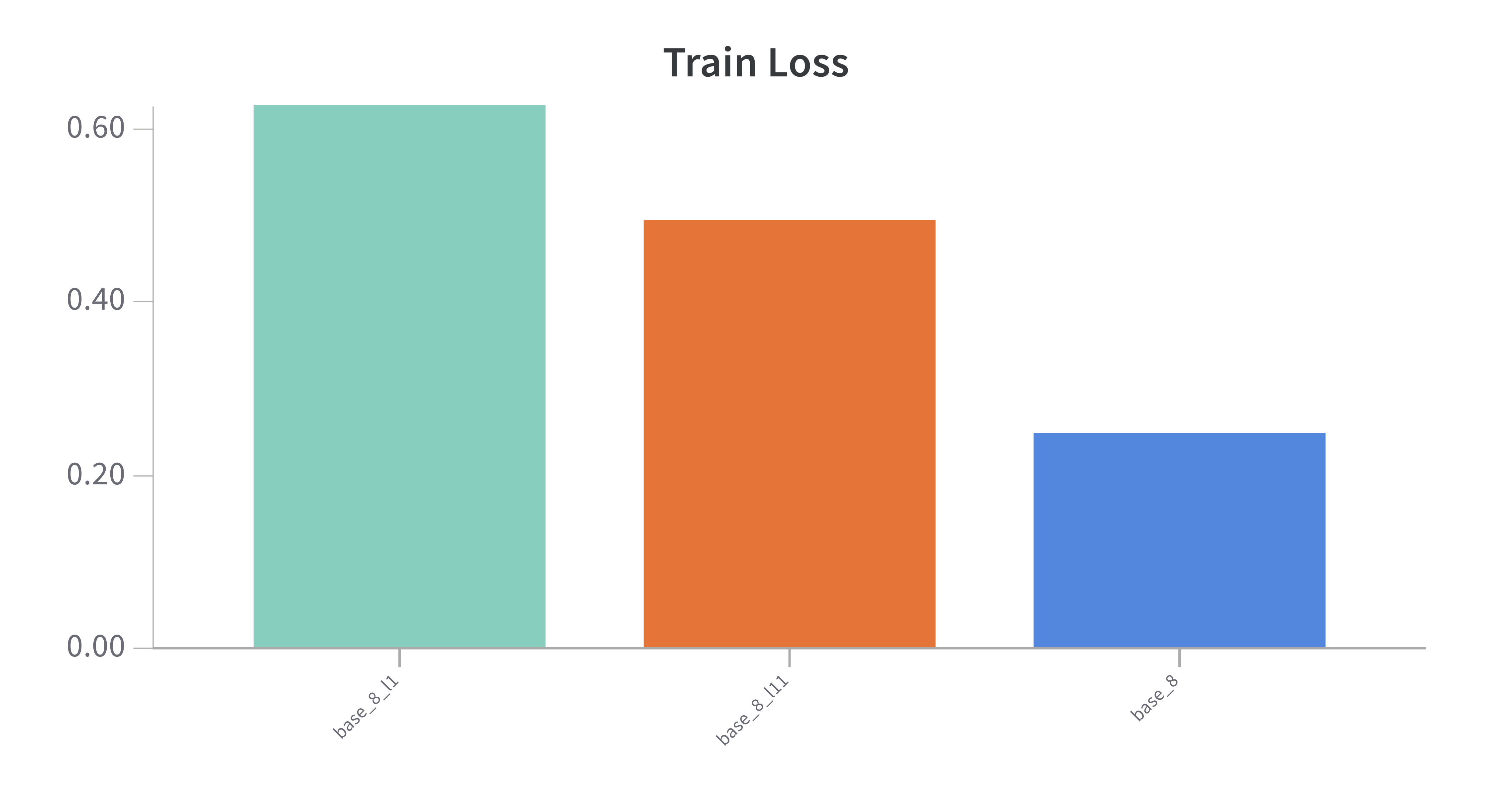
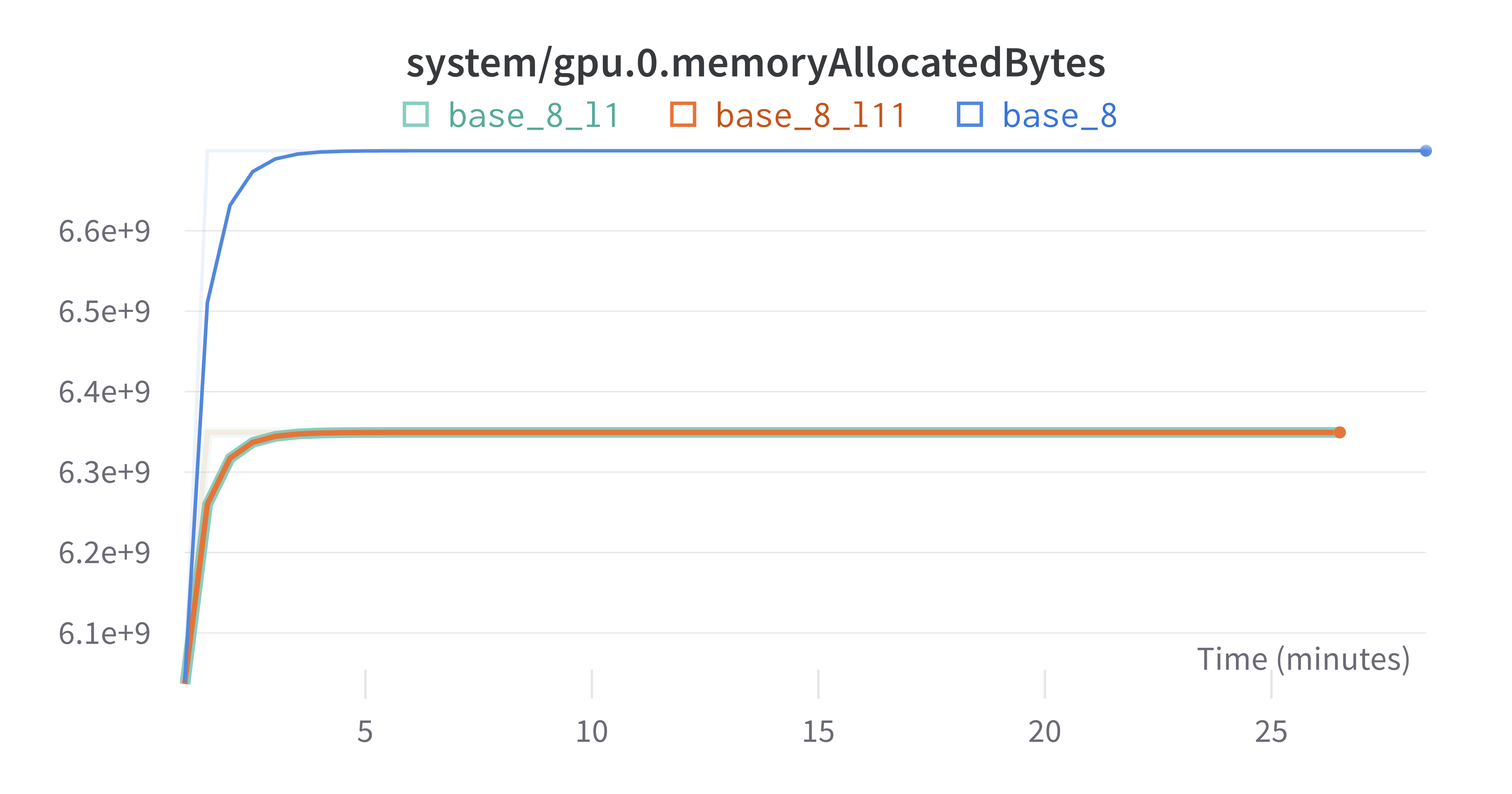
LORA Layers
LORA is implemented so that each of the 12 encoder layers in BERT have the dimension reducing linear layer interwoven. I had the hypothesis that earlier LORA layers would take longer to train because more backpropagation was required to update the parameters. However, this was empirically shown to be wrong as training the first layer only or the last layer only took the same amount of time. Presumably this is because there are no optimizations that check for how deep backprop needs to go - eg, "if the params are frozen, stop". Note that there are ~150k trainable params in the BERT implentation of LORA, with a single layer having ~15k. BERT overall has ~100M parameters.
Results:
- Training a single layer was 8% faster than training all 12 layers, but there was no difference in timing between training the first and last layer.
- The GPU memory used was only nominally lower for one layer than the base case (all layers), presumably from not needing the ~135k gradients. Given there are >100M parameters overall, this demonstrates that the LORA layers alone are nominal relative to all BERT params, having a marginal impact on the overall training fixed overhead.
- Finally, performance was markedly worse when training only one layer. If you had to choose, training the later layer yields better performance, consistent with the other approaches of fine-tuning the last layers.