Fine-tuning BERT with LORA and WandB
deep-learning llms tutorial Overview
In this post, I look at fine-tuning a BERT Sequence Classification model, which is the original pre-trained BERT model with a classification head. The goal was to assess performance of the LORA adapter from a metric and training ease. It was the first time I used WandB and was very impressed with the seamless integration and useful metrics to help inform trianing. All code for this project can be found here.
ChatGPT has ignited a flurry of interest in large language models. This interest has opened new use cases for which older transformers could effectively solve. While temping to take the sledgehammer to the peanut, there are advantages in using the smaller models. They are easier to fine-tune and the infrastructure requirements are significantly reduced.
Results
Below are the 6 configurations in increasing order of complexity, along with the trainable parameters (note that there are all params: 108,311,810 in all for BERT):
- No trianing:
trainable params: 0 - Training classifier head only:
trainable params: 1,538 - Training classifier head + first layer:
trainable params: 7,089,410 - Training classifier head + first two layers:
trainable params: 14,177,282 - Training LORA adapter (r=4):
trainable params: 150,532 - Training full model:
trainable params: 108,311,810
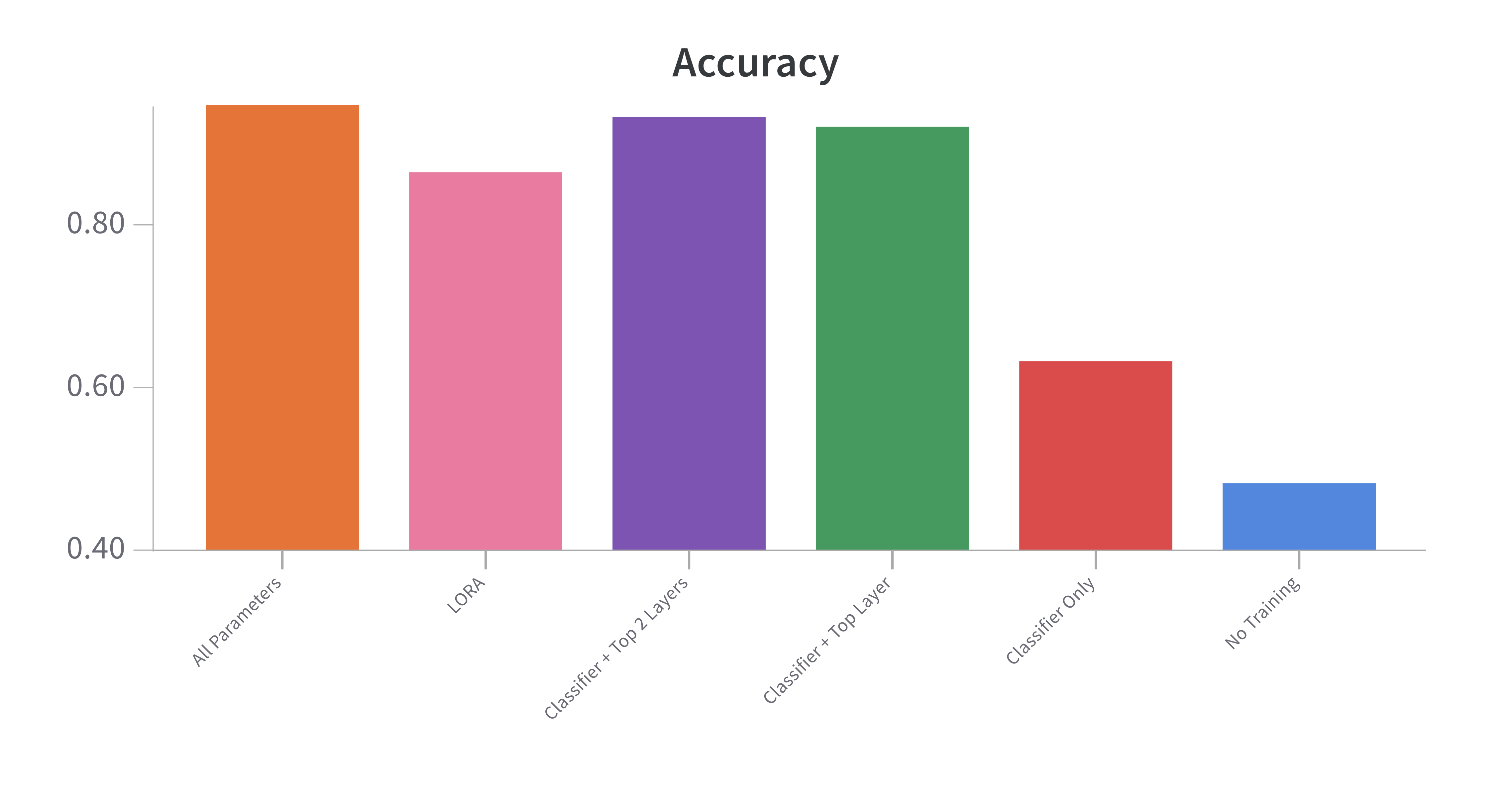
The performance showed a monotonic increase as more parameters are trained (accept for lora), which wasn't necessarily surprising. However, the degree in effectiveness was. In particular, training the classifier alone was not very effective. It was very important to include the first layer, with marginal improvement going deeper into the network. Note that this could be because I stopped at 10k training samples and 2k test samples.
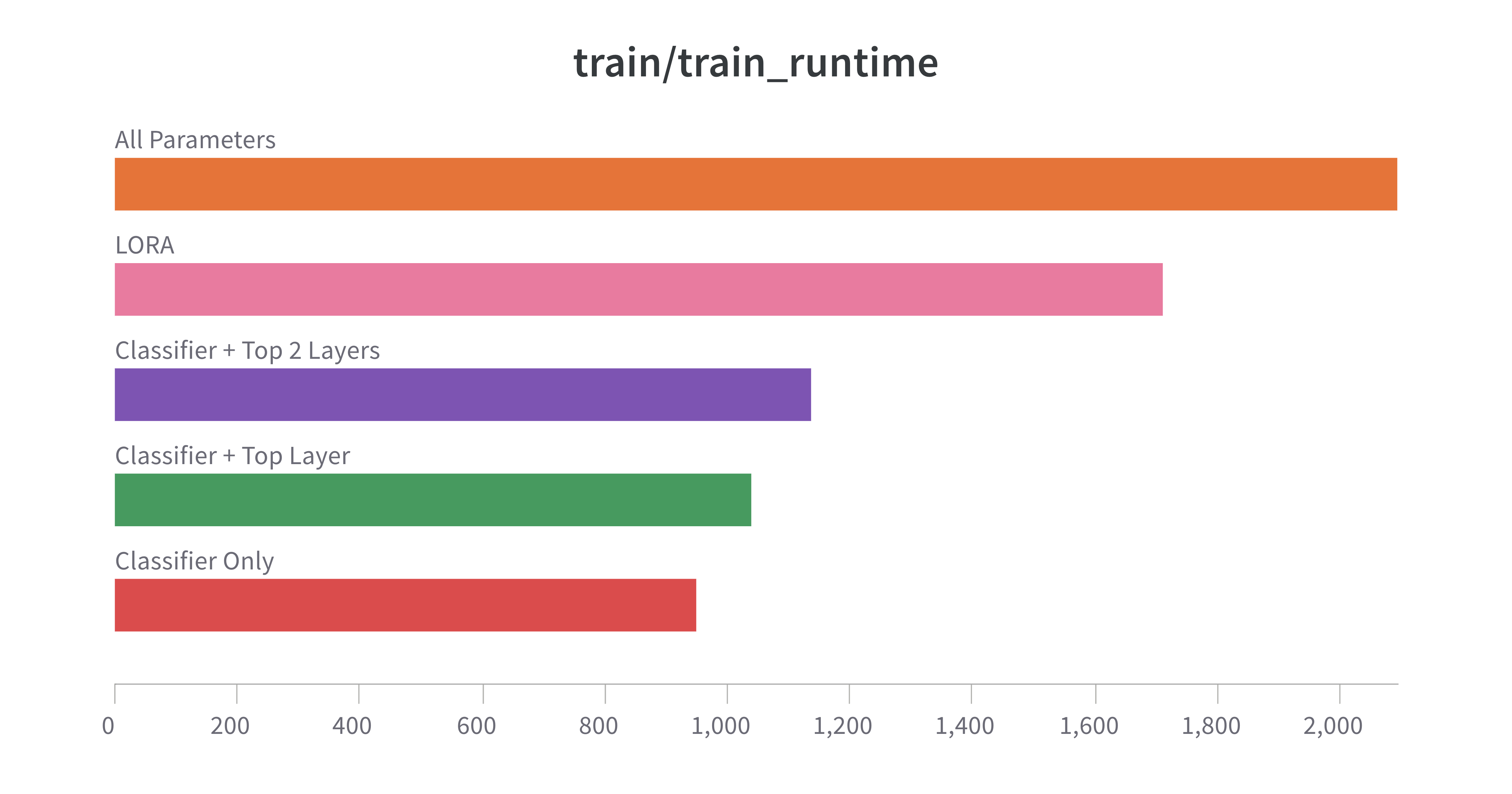
Open Question: LORA Training time
I was able to run this on my Mac M1 with reasonable time, except for LORA and Full Training. While I expected this for the latter, I am not completely clear on the former. I ended up doing all training in Colab using the T4 GPU runtime. I will be spending some time understanding why I couldn't get LORA to run locally on an M1, given that there are much less parameters to tune.
Code Details
Defining the training and test datasets
I used the yelp_polarity dataset, which consists of reviews and a binary label for positive / negative. The get_dataset function does the processing. Only two actions are really needed. One was to cap the number of rows so that I could train on my Mac (although I ultimately moved to Colab for LORA). When capping the rows, it is important to randomize the sampling. The second action is to tokenize the text using the .
Defining the metrics for the trainer
This tutorial gives a good description of how to create a compute_metrics function. I extended it to return 3 metrics. In the trainer argument class, you can specify how many steps before the evaluation will take place. It is not very intuitive, but the training process will run the evaluation after that many steps, but it will not run at the end. The evaluate function needs to be called for that to take place. In addition, I implemented a PerformanceBenchmark class to confirm that the trainer returned the equivalent value.
Instantiating the trainer for LORA
LORA, introduced here, is implemented in the PEFT implementation. This implentation makes it very easy to instantiate. And the size of the adapters are very small in memory. However, despite having 1/20th the parameters, it took almost twice as long on a GPU and impossibly long on an M1. I believe there's probably some implementation optimization that is needed. Using the System WandB logs will be helpful in debugging this.
Observing the outputs on WandB
Integrating the Trainer run with WandB allows for an easy way to analyze the training details. When performing multiple runs with different configurations, it is important be able to track your experiments. For a particular set of experiements, you define a Project, and the individual experiments are called Runs. Beyond setting up an account, I found the following to be helpful:- In TrainerArguments, set the report_to parameter to wandb and use the run_name parameter to set the particular experiment.
- In your .env file, set the following: WANDB_API_KEY, WANDB_DISABLED (set to false), WANDB_PROJECT, and WANDB_LOG_MODEL.
- When the run is done, use wandb.finish() to ensure the run is acknowledged as complete.