Improving Retrieval w Finetuned Embeddings
deep-learning llms tutorial In my previous post on RAG, we saw that performance is limited by the quality of the retriever. Inspired by a recent talk by Jerry Liu from LlamaIndex, we explore in this post how to finetune the retriever to improve performance. The focus is on implementation and not results, which will be covered in a future post. This is mostly because we use a the bare minimum dataset (1 pdf!) and do no hyperparameter tuning. In addition, the abstraction provided by LlamaIndex does not make detailed evaluation easy, so we will have to go under the covers a bit.
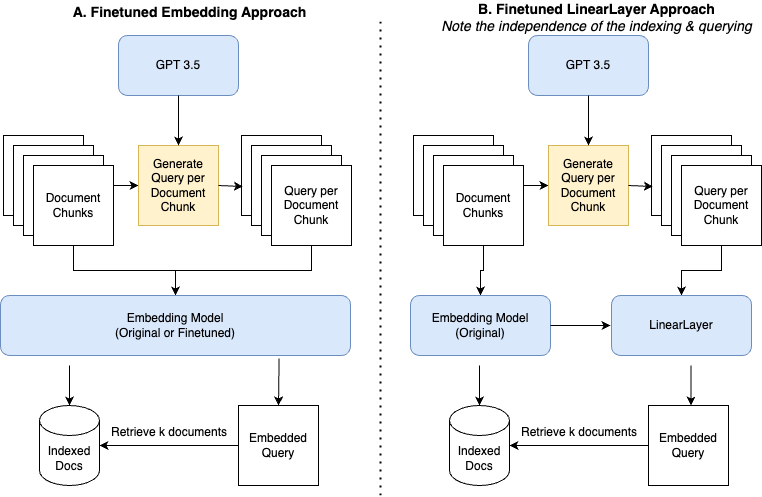
We follow LlamaIndex materials (references below) on finetuning embeddings with the objective of retrieval. In addition, we will also implement the linear adapter approach, which is a linear layer trained on top of the embedding layer. Here, we use llama_index's implementation, but in a future post, we will implement the details.
There are two novel components I observed: first was their insight on how to create the dataset and second is the idea of a linear adapter.
To create the dataset, they use the doc chunks as a starting point and then layer GPT to identify a relevant query for the doc chunk. The query is then used to create a positive example. For a single doc, this creates ~200 positive examples. Negative samples are not used and thus the training objective is MultipleNegativesRankingLoss.
The linear adapter has the benefit of being lightweight to train and more importantly, the doc chunks do not need to be re-indexed after training. In the evaluation section, note how the performance is measured after the docs are re-indexed using the finetuned model, except in the case of the linear adapter.
The evaluation shows that the finetuned models do worse than the original, but this could be for a number of reasons. In a future post, when we deeper dive into the finetuning process, we will explore this further.
The outline is as follows:
- Load the documents and parse them
- Create the dataset using GPT
- Finetune the model
3a. Finetuning the entire model wo a wrapper
3b. Finetuning the entire model with a wrapper
3c. Finetuning the an adapter layer with a wrapper - Evaluate the original and the finetuned models
References:
from src.logger import logger
1. Load docs and Parse¶
from llama_index import SimpleDirectoryReader
from llama_index.node_parser import SimpleNodeParser
TRAIN_FILES = ["data/amazon_10k_2022.pdf"]
VAL_FILES = ["data/apple_10k_2022.pdf"]
TRAIN_CORPUS_FPATH = "./data/train_corpus.json"
VAL_CORPUS_FPATH = "./data/val_corpus.json"
train_reader = SimpleDirectoryReader(input_files=TRAIN_FILES)
train_docs = train_reader.load_data()
train_parser = SimpleNodeParser.from_defaults()
train_nodes = train_parser.get_nodes_from_documents(train_docs, show_progress=True)
Parsing documents into nodes: 0%| | 0/81 [00:00<?, ?it/s]
val_reader = SimpleDirectoryReader(input_files=VAL_FILES)
val_docs = val_reader.load_data()
val_parser = SimpleNodeParser.from_defaults()
val_nodes = val_parser.get_nodes_from_documents(val_docs, show_progress=True)
Parsing documents into nodes: 0%| | 0/80 [00:00<?, ?it/s]
train_nodes[0].text[:100] #sample text
'Table of Contents\nUNITED STATES\nSECURITIES AND EXCHANGE COMMISSION\nWashington, D.C. 20549\n _________'
1A. Plot hist of doc lengths¶
import matplotlib.pyplot as plt
plt.hist([len(t.text.split(' ')) for t in train_nodes])
plt.title("Histogram of number of words in each node")
Text(0.5, 1.0, 'Histogram of number of words in each node')

plt.hist([len(t.text) for t in train_nodes])
plt.title("Histogram of number of characters in each node")
Text(0.5, 1.0, 'Histogram of number of characters in each node')

2. Generate synthetic Queries¶
The star of this show is the helper function generate_qa_embedding_pairs (see code for more detail) which generates a EmbeddingQAFinetuneDataset, a dataset with doc chunks, the relevant query and a mapping.
from llama_index.finetuning import generate_qa_embedding_pairs, EmbeddingQAFinetuneDataset
import os
from dotenv import load_dotenv
load_dotenv('.env')
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
from llama_index.llms import OpenAI
llm = OpenAI(model='gpt-3.5-turbo', api_key=OPENAI_API_KEY)
rerun_qa_pairs = False
if rerun_qa_pairs:
logger.info("Generating QA pairs for training")
train_dataset = generate_qa_embedding_pairs(train_nodes, llm=llm)
train_dataset.save_json("data/train_dataset.json")
logger.info("Generating QA pairs for validation")
val_dataset = generate_qa_embedding_pairs(val_nodes, llm=llm)
val_dataset.save_json("data/val_dataset.json")
else:
train_dataset = EmbeddingQAFinetuneDataset.from_json("data/train_dataset.json")
val_dataset = EmbeddingQAFinetuneDataset.from_json("data/val_dataset.json")
list(train_dataset.queries.items())[0] #sample query
('aeb23b8d-cc0e-4733-a3bb-0428cbe6d9b4',
'According to the context information provided, what is the trading symbol for Amazon.com, Inc. on the Nasdaq Global Select Market?')
list(train_dataset.corpus.items())[0] #sample answer
('167c6445-996c-41f4-80cf-cb84f8f57699',
'Table of Contents\nUNITED STATES\nSECURITIES AND EXCHANGE COMMISSION\nWashington, D.C. 20549\n ____________________________________\nFORM 10-K\n____________________________________ \n(Mark One)\n☒ ANNUAL REPOR T PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934\nFor the fiscal year ended December 31, 2022\nor\n☐ TRANSITION REPOR T PURSUANT TO SECTION 13 OR 15(d) OF THE SECURITIES EXCHANGE ACT OF 1934\nFor the transition period from to .Commission File No.000-22513\n____________________________________\nAMAZON .COM, INC.\n(Exact name of registrant as specified in its charter)\nDelaware 91-1646860\n(State or other jurisdiction of\nincorporation or organization) (I.R.S.Employer\nIdentification No.)410 Terry Avenue North\nSeattle, Washington 98109-5210\n(206) 266-1000\n(Addr ess and telephone number , including ar ea code, of r egistrant’ s principal executive offices)\nSecurities registered pursuant to Section 12(b) of the Act:\nTitle of Each Class Trading Symbol(s) Name of Each Exchange on Which Registered\nCommon Stock, par value $.01 per share AMZN Nasdaq Global Select Market\nSecurities registered pursuant to Section 12(g) of the Act:\nNone\n ____________________________________\nIndicate by check mark if the registrant is a well-known seasoned issuer, as defined in Rule 405 of the Securities Act.Yes ☒ No ☐\nIndicate by check mark if the registrant is not required to file reports pursuant to Section 13 or Section 15(d) of the Exchange Act.Yes ☐ No ☒\nIndicate by check mark whether the registrant (1) has filed all reports required to be filed by Section 13 or 15(d) of the Securities Exchange Act of 1934 during the preceding 12 months (or for\nsuch shorter period that the registrant was required to file such reports), and (2) has been subject to such filing requirements for the past 90 days.Yes ☒ No ☐\nIndicate by check mark whether the registrant has submitted electronically every Interactive Data File required to be submitted pursuant to Rule 405 of Regulation S-T during the preceding 12\nmonths (or for such shorter period that the registrant was required to submit such files).Yes ☒ No ☐\nIndicate by check mark whether the registrant is a large accelerated filer, an accelerated filer, a non-accelerated filer, a smaller reporting company, or an emerging growth company.See the\ndefinitions of “large accelerated filer,” “accelerated filer,” “smaller reporting company,” and “emerging growth company” in Rule 12b-2 of the Exchange Act.Large accelerated filer ☒ Accelerated filer ☐\nNon-accelerated filer ☐ Smaller reporting company ☐\nEmerging growth company ☐\nIf an emerging growth company, indicate by check mark if the registrant has elected not to use the extended transition period for complying with any new or revised financial accounting\nstandards provided pursuant to Section 13(a) of the Exchange Act.☐\nIndicate by check mark whether the registrant has filed a report on and attestation to its management’s assessment of the effectiveness of its internal control over financial reporting under Section\n404(b) of the Sarbanes-Oxley Act (15 U.S.C.7262(b)) by the registered public accounting firm that prepared or issued its audit report.☒\nIndicate by check mark whether the registrant is a shell company (as defined in Rule 12b-2 of the Exchange Act).')
list(train_dataset.relevant_docs.items())[0] #sample relevant doc
('aeb23b8d-cc0e-4733-a3bb-0428cbe6d9b4',
['167c6445-996c-41f4-80cf-cb84f8f57699'])
3A. Finetuning w Wrapper¶
from llama_index.finetuning import SentenceTransformersFinetuneEngine
finetune_engine = SentenceTransformersFinetuneEngine(
train_dataset,
model_id="BAAI/bge-small-en",
model_output_path="model/test_model",
val_dataset=val_dataset,
)
finetune_engine.finetune()
model_finetune_wrapper = finetune_engine.get_finetuned_model()
model_finetune_wrapper
Epoch: 0%| | 0/2 [00:00<?, ?it/s]
Iteration: 0%| | 0/20 [00:00<?, ?it/s]
Iteration: 0%| | 0/20 [00:00<?, ?it/s]
LangchainEmbedding(model_name='model/test_model', embed_batch_size=10, callback_manager=<llama_index.callbacks.base.CallbackManager object at 0x29064a4d0>)
3B. Fine tuning w/o Wrapper¶
Using this LlamaIndex code
from sentence_transformers import SentenceTransformer
model_id = "BAAI/bge-small-en"
model_finetune_wo_wrapper = SentenceTransformer(model_id)
model_finetune_wo_wrapper
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': True}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
3B_1. DataLoader¶
import json
from torch.utils.data import DataLoader
from sentence_transformers import InputExample
TRAIN_DATASET_FPATH = './data/train_dataset.json'
VAL_DATASET_FPATH = './data/val_dataset.json'
# We use a very small batchsize to run this toy example on a local machine.
# This should typically be much larger.
BATCH_SIZE = 10
with open(TRAIN_DATASET_FPATH, 'r+') as f:
train_dataset = json.load(f)
with open(VAL_DATASET_FPATH, 'r+') as f:
val_dataset = json.load(f)
corpus = train_dataset['corpus']
queries = train_dataset['queries']
relevant_docs = train_dataset['relevant_docs']
examples = []
for query_id, query in queries.items():
node_id = relevant_docs[query_id][0]
text = corpus[node_id]
example = InputExample(texts=[query, text])
examples.append(example)
train_loader = DataLoader(examples, batch_size=BATCH_SIZE)
from sentence_transformers import losses
loss = losses.MultipleNegativesRankingLoss(model_finetune_wo_wrapper)
3B_3 Evaluator¶
from sentence_transformers.evaluation import InformationRetrievalEvaluator
corpus = val_dataset['corpus']
queries = val_dataset['queries']
relevant_docs = val_dataset['relevant_docs']
evaluator = InformationRetrievalEvaluator(queries, corpus, relevant_docs)
3B_4 Training¶
EPOCHS = 2
warmup_steps = int(len(train_loader) * EPOCHS * 0.1)
warmup_steps
4
model_finetune_wo_wrapper.fit(
train_objectives=[(train_loader, loss)],
epochs=EPOCHS,
warmup_steps=warmup_steps,
output_path='model/exp_finetune',
show_progress_bar=True,
evaluator=evaluator,
evaluation_steps=50,
)
Epoch: 0%| | 0/2 [00:00<?, ?it/s]
Iteration: 0%| | 0/20 [00:00<?, ?it/s]
Iteration: 0%| | 0/20 [00:00<?, ?it/s]
3C Fine tuning w Adapter (w Wrapper)¶
from llama_index.finetuning import EmbeddingAdapterFinetuneEngine
from llama_index.embeddings import resolve_embed_model
import torch
base_embed_model = resolve_embed_model("local:BAAI/bge-small-en")
base_embed_model
LangchainEmbedding(model_name='BAAI/bge-small-en', embed_batch_size=10, callback_manager=<llama_index.callbacks.base.CallbackManager object at 0x2a701fc50>)
train_dataset = EmbeddingQAFinetuneDataset.from_json("data/train_dataset.json")
finetune_engine = EmbeddingAdapterFinetuneEngine(
train_dataset,
base_embed_model,
model_output_path="model/linear_adapter_model_output",
# bias=True,
epochs=4,
verbose=True,
# optimizer_class=torch.optim.SGD,
# optimizer_params={"lr": 0.01}
)
finetune_engine.finetune()
model_finetune_adapter = finetune_engine.get_finetuned_model()
model_finetune_adapter
> Prepared optimizer, scheduler, and loss model.
Epoch: 0%| | 0/4 [00:00<?, ?it/s]
Iteration: 0%| | 0/20 [00:00<?, ?it/s]
> [Epoch 0] Current loss: 1.5378854274749756 > [Epoch 0] Current loss: 1.6346807479858398 > [Epoch 0] Current loss: 1.6413780450820923 > [Epoch 0] Current loss: 1.6350507736206055 > [Epoch 0] Current loss: 1.5301778316497803 > [Epoch 0] Current loss: 1.4437916278839111 > [Epoch 0] Current loss: 1.6945806741714478 > [Epoch 0] Current loss: 1.556748628616333 > [Epoch 0] Current loss: 1.4235153198242188 > [Epoch 0] Current loss: 1.8829962015151978 > [Epoch 0] Current loss: 1.627474069595337 > [Epoch 0] Current loss: 1.7111928462982178 > [Epoch 0] Current loss: 1.7029794454574585 > [Epoch 0] Current loss: 1.4477611780166626 > [Epoch 0] Current loss: 1.4704334735870361 > [Epoch 0] Current loss: 1.6094467639923096 > [Epoch 0] Current loss: 1.3818140029907227 > [Epoch 0] Current loss: 1.6748864650726318 > [Epoch 0] Current loss: 1.5955607891082764 > [Epoch 0] Current loss: 1.6909136772155762
Iteration: 0%| | 0/20 [00:00<?, ?it/s]
> [Epoch 1] Current loss: 1.5261491537094116 > [Epoch 1] Current loss: 1.6243072748184204 > [Epoch 1] Current loss: 1.6313021183013916 > [Epoch 1] Current loss: 1.6240249872207642 > [Epoch 1] Current loss: 1.51425302028656 > [Epoch 1] Current loss: 1.4318571090698242 > [Epoch 1] Current loss: 1.6842161417007446 > [Epoch 1] Current loss: 1.5474557876586914 > [Epoch 1] Current loss: 1.4090734720230103 > [Epoch 1] Current loss: 1.8755619525909424 > [Epoch 1] Current loss: 1.6179897785186768 > [Epoch 1] Current loss: 1.7022966146469116 > [Epoch 1] Current loss: 1.6934553384780884 > [Epoch 1] Current loss: 1.438105583190918 > [Epoch 1] Current loss: 1.4624629020690918 > [Epoch 1] Current loss: 1.598638892173767 > [Epoch 1] Current loss: 1.3725802898406982 > [Epoch 1] Current loss: 1.665087103843689 > [Epoch 1] Current loss: 1.5869908332824707 > [Epoch 1] Current loss: 1.6854139566421509
Iteration: 0%| | 0/20 [00:00<?, ?it/s]
> [Epoch 2] Current loss: 1.5153812170028687 > [Epoch 2] Current loss: 1.6158387660980225 > [Epoch 2] Current loss: 1.6236436367034912 > [Epoch 2] Current loss: 1.6161752939224243 > [Epoch 2] Current loss: 1.503255844116211 > [Epoch 2] Current loss: 1.423755407333374 > [Epoch 2] Current loss: 1.6774322986602783 > [Epoch 2] Current loss: 1.5415922403335571 > [Epoch 2] Current loss: 1.399795651435852 > [Epoch 2] Current loss: 1.8707644939422607 > [Epoch 2] Current loss: 1.611924171447754 > [Epoch 2] Current loss: 1.696466088294983 > [Epoch 2] Current loss: 1.6872295141220093 > [Epoch 2] Current loss: 1.431787133216858 > [Epoch 2] Current loss: 1.4573103189468384 > [Epoch 2] Current loss: 1.5916310548782349 > [Epoch 2] Current loss: 1.366682767868042 > [Epoch 2] Current loss: 1.6588109731674194 > [Epoch 2] Current loss: 1.5815335512161255 > [Epoch 2] Current loss: 1.6818515062332153
Iteration: 0%| | 0/20 [00:00<?, ?it/s]
> [Epoch 3] Current loss: 1.5089690685272217 > [Epoch 3] Current loss: 1.610770583152771 > [Epoch 3] Current loss: 1.6191225051879883 > [Epoch 3] Current loss: 1.6116206645965576 > [Epoch 3] Current loss: 1.4969731569290161 > [Epoch 3] Current loss: 1.419163703918457 > [Epoch 3] Current loss: 1.6736475229263306 > [Epoch 3] Current loss: 1.5384052991867065 > [Epoch 3] Current loss: 1.3947967290878296 > [Epoch 3] Current loss: 1.8682200908660889 > [Epoch 3] Current loss: 1.6087634563446045 > [Epoch 3] Current loss: 1.6934829950332642 > [Epoch 3] Current loss: 1.6841280460357666 > [Epoch 3] Current loss: 1.42873215675354 > [Epoch 3] Current loss: 1.4548718929290771 > [Epoch 3] Current loss: 1.5884225368499756 > [Epoch 3] Current loss: 1.364109754562378 > [Epoch 3] Current loss: 1.6561272144317627 > [Epoch 3] Current loss: 1.5792872905731201 > [Epoch 3] Current loss: 1.6804169416427612 > Finished training, saving to model/linear_adapter_model_output
LinearAdapterEmbeddingModel(model_name='Adapter for BAAI/bge-small-en', embed_batch_size=10, callback_manager=<llama_index.callbacks.base.CallbackManager object at 0x2969a65d0>)
4 Evaluate¶
from llama_index.embeddings import OpenAIEmbedding
from llama_index import ServiceContext, VectorStoreIndex
from llama_index.schema import TextNode
from tqdm.notebook import tqdm
import pandas as pd
def evaluate(dataset, embed_model, adapter=None, top_k=5, verbose=False,):
corpus = dataset.corpus
queries = dataset.queries
relevant_docs = dataset.relevant_docs
logger.info(f"Using embed model {embed_model}")
service_context = ServiceContext.from_defaults(embed_model=embed_model)
nodes = [TextNode(id_=id_, text=text) for id_, text in corpus.items()]
index = VectorStoreIndex(nodes, service_context=service_context, show_progress=True)
if adapter:
logger.info(f"Using adapter {adapter}")
index.service_context.embed_model = adapter
retriever = index.as_retriever(similarity_top_k=top_k)
eval_results = []
for query_id, query in tqdm(queries.items()):
retrieved_nodes = retriever.retrieve(query)
retrieved_ids = [node.node.node_id for node in retrieved_nodes]
expected_id = relevant_docs[query_id][0]
is_hit = expected_id in retrieved_ids # assume 1 relevant doc
eval_result = {
"is_hit": is_hit,
"retrieved": retrieved_ids,
"expected": expected_id,
"query": query_id,
}
eval_results.append(eval_result)
return eval_results
val_dataset = EmbeddingQAFinetuneDataset.from_json("data/val_dataset.json")
# OpenAI Embedding Model
ada = OpenAIEmbedding(api_key=OPENAI_API_KEY)
ada_val_results = evaluate(val_dataset, ada)
df_ada = pd.DataFrame(ada_val_results)
hit_rate_ada = df_ada["is_hit"].mean()
print(hit_rate_ada)
2023-09-10 11:43:54,484 - src.logger - INFO - Using embed model model_name='text-embedding-ada-002' embed_batch_size=10 callback_manager=<llama_index.callbacks.base.CallbackManager object at 0x28f8dbd10> deployment_name=None openai_kwargs={'api_key': 'sk-'}
Generating embeddings: 0%| | 0/102 [00:00<?, ?it/s]
0%| | 0/204 [00:00<?, ?it/s]
0.9705882352941176
# Original Embedding Model
bge = "local:BAAI/bge-small-en"
bge_val_results = evaluate(val_dataset, bge)
df_bge = pd.DataFrame(bge_val_results)
hit_rate_bge = df_bge["is_hit"].mean()
hit_rate_bge
2023-09-10 11:46:13,010 - src.logger - INFO - Using embed model local:BAAI/bge-small-en
Generating embeddings: 0%| | 0/102 [00:00<?, ?it/s]
0%| | 0/204 [00:00<?, ?it/s]
0.9215686274509803
# Embedding Model Finetuned w Wrapper
val_results_finetuned_wrapper = evaluate(val_dataset, model_finetune_wrapper)
df_finetune_wrapper = pd.DataFrame(val_results_finetuned_wrapper)
hit_rate_finetune_wrapper = df_finetune_wrapper["is_hit"].mean()
print(hit_rate_finetune_wrapper)
2023-09-10 11:46:35,047 - src.logger - INFO - Using embed model model_name='model/test_model' embed_batch_size=10 callback_manager=<llama_index.callbacks.base.CallbackManager object at 0x29064a4d0>
Generating embeddings: 0%| | 0/102 [00:00<?, ?it/s]
0%| | 0/204 [00:00<?, ?it/s]
0.9117647058823529
# Embedding Model Finetuned wo Wrapper (should give same results?)
val_results_finetuned_wo_wrapper = evaluate(val_dataset, 'local:model/exp_finetune')
df_finetune_wo_wrapper = pd.DataFrame(val_results_finetuned_wo_wrapper)
hit_rate_finetune_wo_wrapper = df_finetune_wo_wrapper["is_hit"].mean()
print(hit_rate_finetune_wo_wrapper)
2023-09-10 11:46:56,081 - src.logger - INFO - Using embed model local:model/exp_finetune
Generating embeddings: 0%| | 0/102 [00:00<?, ?it/s]
0%| | 0/204 [00:00<?, ?it/s]
0.9068627450980392
# Embedding Model Finetuned Adapter
val_results_adapter = evaluate(train_dataset, base_embed_model, model_finetune_adapter)
df_adapter = pd.DataFrame(val_results_adapter)
hit_rate_adapter = df_adapter["is_hit"].mean()
print(hit_rate_adapter)
2023-09-10 11:47:16,746 - src.logger - INFO - Using embed model model_name='BAAI/bge-small-en' embed_batch_size=10 callback_manager=<llama_index.callbacks.base.CallbackManager object at 0x2a701fc50>
Generating embeddings: 0%| | 0/99 [00:00<?, ?it/s]
2023-09-10 11:47:29,792 - src.logger - INFO - Using adapter model_name='Adapter for BAAI/bge-small-en' embed_batch_size=10 callback_manager=<llama_index.callbacks.base.CallbackManager object at 0x2969a65d0>
0%| | 0/198 [00:00<?, ?it/s]
0.9090909090909091