LLMs Part 1: The Context for Recent AI Developments
llms strategy tutorial finance Introduction
There has been a Cambrian explosion of generative AI models, popularized by OpenAI’s ChatGPT. This reflects the overnight success after decades of work in the NLP space. In fact, some experts suggest that ChatGPT is ‘not particularly innovative’. After many decades of slow progress, the 2010s showed great promise. Between 2015-2018, LSTM improved the state of the art. However, it was the Transformer from Google in 2017 that was largley responsible for the current hype around Generative AI. The breakneck speed of development in this area makes it hard to keep track of the current state, even for experts. It is even harder to forecast how these models can be leveraged to enhance business processes, both for efficiency and informing investment processes for traders and portfolio managers. Thus, the keen student will listen for tense when speaking about the subject. It is easy to make predictions about the future and be wrong. Past and present tense is a good place to start when the interest is for practical implications.
A Very Brief History of LLMs
The invention of the Transformer architecture could be considered the genesis of this current wave of Large Language Models (LLMs). It allows models to achieve large scale with two novel features. First, it allows for parallel processing, in place of sequential processing, thus reducing training time. Second, the self-attention mechanism allows each step to have access to all other steps. With the Transformer, the arms race had begun. Model scales ballooned from 345M BERT (2018) to 1.5B GPT-2 (2019) to 175B GPT-3 (2020) and to the newest models with 500B+ (PaLM, GPT-4). The size of the model reflects its capacity to encode digitized human knowledge. There was an observed phase shift at ~50B parameters that resulted in emergent abilities. These novel features set off the imagination and created a shift in language research from “task-specific models to large foundational models”.
LLM Proliferation - It’s Not Just ChatGPT
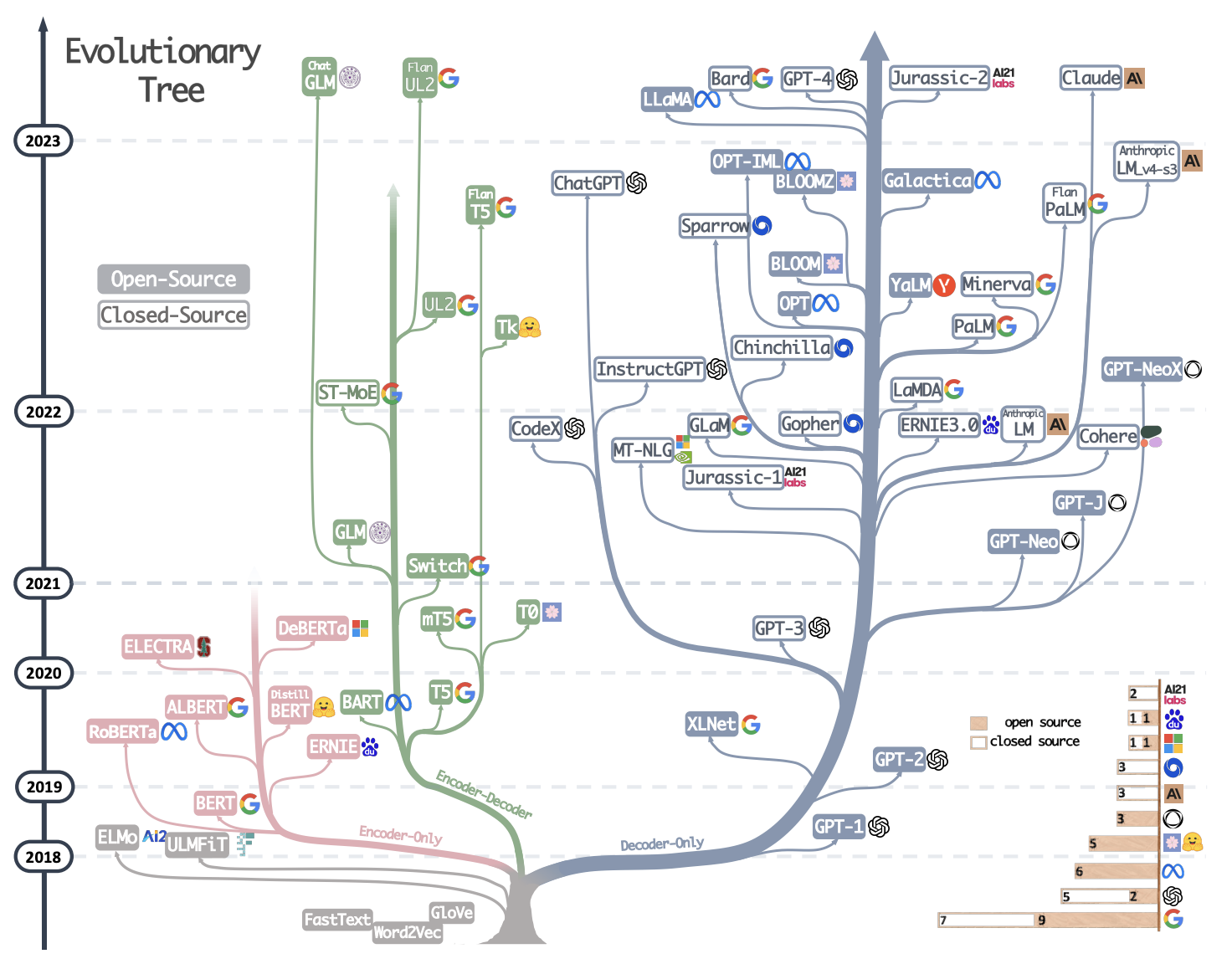
While OpenAI’s ChatGPT has captured the imagination of the general public, the LLM landscape is vast and growing rapidly with several closed and open source alternatives. Figure 1 is a good illustration with a timeline, taxonomy, and company association. Listing out the plethora of models is a cottage industry. Table 1 gives 5 good references listing out models.
Table 2 is my own curated list by company. The largest publicly traded companies, Meta, Google and Microsoft, all have different business model approaches to LLMs. Meta is open sourcing with the idea that it benefits from an ecosystem for users. Microsoft seems to be content with an OpenAI partnership and is busy integrating into their product suite. Google has been the intellectual giant and leader in the space, inventing the transformer, but has largely been criticized for not leveraging fully. In the recent I/O, they created some excitement around monetization within their own product suite, although the impact remains to be seen.
| Source Enumerating LLMs | Comments |
|---|---|
| Ecosystems Graphs website | Has a table with dependency graph; comprehensive, but might be too much information. |
| A Survey on ChatGPT and Beyond | Paper. Nice picture showing LLM etymology (reproduced here). Good discussion on practical usage. |
| The Ultimate Battle of Language Models | Includes the model sizes and licensing information, which has useful practical implications. |
| LLaMA-Cult-and-More overview table | FNice for fine tuning information. |
| A Survey of Large Language Models | Comprehensive paper. Good understanding of history, evaluation techniques and available tools. |
| Company | Market Cap / Valuation (as of May ‘23) |
Model Name (all text-to-text unless otherwise indicated) |
|---|---|---|
| OpenAI | $30B (Private, est) | GPT series, DALL-E (image), Codex (code) |
| Meta | $630B (Public) | LLAMA, Galactica, ImageBind, DinoV2, SegmentAnything, SpeechFromBrain, iPEER |
| $1.5T (Public) | PaLM, LaMDA, FLAN | |
| DeepMind | Subsidiary of Google | Chinchilla, Gopher, Flamingo, AlphaCode |
| HuggingFace | $2B (Private, est) | CodeGen, BLOOM |
| Other | n/a | StableDiffusion (Runway), Midjourney (LeapMotion) |
| Microsoft | $2.4T | Notably, have partnered with OpenAI and have no specific model they have advertised themselves. |
GPT Series Explained
GPT gets special mention given its pervasiveness in mainstream culture. Subjectively, the GPT evolution can be segmented into 3 stages based on a survey paper. Note that while the original Transformer follows an encoder-decoder architecture, the GPT series uses a lightly modified version, which is decoder only. Figure 1 shows how it is mostly Google (which has models in both types) that is still continuing to follow the encoder-decoder, while most research and development is on the encoder-decoder branch.
Phase 1- Early Explorations: After the Transformer in 2017, GPT1 came out in 2018 with 120M parameters, followed by GPT-2 in 2019 with 1.5B parameters.
Phase 2- Capacity Leap: In 2020, OpenAI released GPT-3 with 175B parameters. Emergent abilities was a notable feature where in-context learning (ICL) allowed for zero- and few- shot learning. There are no specific number of parameters required to be an LLM, but somewhere at the 50-100B mark there is a phase shift in model behavior, and is commonly recognized (subjectively) as the threshold. .
Phase 3- Capacity Enhancement: Beyond GPT-3, there were two enhancements. First, training on code, which is believed to increase the chain-of-thought prompting abilities. Second, human alignment, which consists of instruction-tuning and is further enhanced with RLHF (reinforcement learning with human feedback). This led to InstructGPT, GPT-3.5, and ChatGPT in November 2022. Finally, GPT-4 was released in 2023 with (purportedly) a whopping 1T parameters.